DeepSeek V4
API Documentation
How to call DeepSeek V4 — endpoints, auth, examples, pricing.
In one paragraph · Last verified 2026-04-27
V4 is OpenAI-API-compatible at https://api.deepseek.com — drop-in for any OpenAI SDK, swap the model to deepseek-v4-pro ($1.74 in / $3.48 out per 1M tokens) or deepseek-v4-flash ($0.14 / $0.28). Output is 7.2× cheaper than Opus 4.7 and 8.6× cheaper than GPT-5.5; V4-Pro is the cheapest frontier option once context exceeds 200K (where Gemini doubles its rates). Both models support hybrid Thinking/Non-Thinking modes, JSON mode (with the explicit “json” prompt requirement), and OpenAI-compatible function calling (with optional strict-mode against a beta endpoint). Available via DeepSeek direct, OpenRouter, NVIDIA NIM (day-0, A100/H100/H200/B200 supported), and DeepInfra.
On this page
Quick start — 60 seconds
export DEEPSEEK_API_KEY="sk-..."
curl https://api.deepseek.com/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-v4-flash",
"messages": [{"role": "user", "content": "Hello in one sentence."}]
}'
That’s it. The API is OpenAI-compatible — drop in https://api.deepseek.com as the base_url of any OpenAI SDK and swap the model to deepseek-v4-flash (cheap, fast) or deepseek-v4-pro (frontier).
If you’re migrating from an existing DeepSeek V3 integration: just change the model parameter. Everything else (auth, base URL, request shape, streaming, tools) is identical. See the dedicated V3 → V4 migration guide.
Choosing V4-Pro vs V4-Flash
The single decision most callers face. The headline tradeoff:
| Axis | V4-Flash favours… | V4-Pro favours… |
|---|---|---|
| Cost (output) | $0.28 / 1M | $3.48 / 1M (12.4× more) |
| Cost (input) | $0.14 / 1M | $1.74 / 1M |
| Reasoning quality | matches V3.x at Max | beats most open models, near-frontier proprietary |
| Long-context recall | OK to ~500K | strong to ~1M (Pro 83.5 vs Flash 78.7 on MRCR 1M) |
| Knowledge breadth | weaker (SimpleQA-Max 34.1) | strong (SimpleQA-Max 57.9) |
| Local deployment | feasible (~170 GB GGUF) | not feasible (~800 GB even at 4-bit) |
| API throughput | higher (smaller active params) | lower per-token (49B active) |
Decision flow
Walk down this list. The first match is your model:
- You need to self-host on consumer or single-server hardware. → Flash. Pro at 1.6T total / 49B active is not realistic outside a cluster.
- Your workload is high-volume and quality is “good enough.” → Flash, default Non-Think. Use Thinking mode selectively when an individual response needs extra effort.
- You’re picking a model for a single-tier production agent that needs to handle anything from chat to multi-step planning. → Pro, with the reasoning-effort axis (Non-Think for simple turns, High for tool-use steps, Max for hard reasoning subtasks).
- Your prompts routinely exceed 200K context. → Pro. Flash’s MRCR fidelity drops past 500K (62.0 vs Pro’s 83.5 on CorpusQA 1M); the cost gap closes once Gemini doubles past 200K (Pro becomes cheapest frontier option).
- You need state-of-the-art knowledge breadth (SimpleQA-class factuality). → Pro Max. SimpleQA-Verified 57.9 vs Flash-Max’s 34.1 is a 24-pp gap — bigger than any reasoning-effort lift Flash gets.
- You’re building a coding-agent fleet running thousands of cheap turns. → Flash with strict prompts. SWE Verified Resolved is 79.0 (Flash-Max) vs 80.6 (Pro-Max) — within 2 pp. Flash makes the per-PR economics work.
- You’re competing with Opus / GPT-5.5 / Gemini 3.1 Pro on hard reasoning benchmarks. → Pro Max. This is the only V4 mode that’s competitive at the frontier.
When to use both
Many production deployments use Flash for the hot path and Pro for the long tail:
- Hot path (90%+ of requests): Flash Non-Think. Cheap, fast, good enough for routine work.
- Escalation (rare hard requests): Pro High or Max. The 12× output cost is amortised over the small fraction of requests that actually need it.
A simple router:
def choose_v4_model(estimated_difficulty: str, context_tokens: int) -> str:
if context_tokens > 500_000:
return "deepseek-v4-pro"
if estimated_difficulty == "hard":
return "deepseek-v4-pro"
return "deepseek-v4-flash"
In practice “estimated_difficulty” is whatever heuristic fits your domain — a classifier on the user query, an LLM-as-judge prefilter, or a tag on the prompt template.
Cost x quality positioning
If you plot output cost (USD/1M) on the x-axis and Artificial Analysis Intelligence Index on the y-axis, V4-Pro and V4-Flash sit at the bottom-left of every other frontier model — same intelligence band, fraction of the cost. See the Artificial Analysis chart for the most current positioning.
Concrete app patterns
Mapping V4 onto seven common build patterns. Cost/req uses the cost calculator at no cache hit — real production with caching often runs 3–5× cheaper.
| Pattern | Variant + mode | Why | Cost/req (no cache) | Key tradeoff |
|---|---|---|---|---|
| Coding agent (Cursor/Aider class) | Flash, Non-Think hot path → Pro High on hard turns | TTFT 300–500ms feels native; Flash Non-Think clears 80% of edits; escalate hard refactors | $0.001–0.005 | If you commit to Flash-only, complex multi-file refactors regress vs Pro-Max |
| Long-document Q&A (multi-PDF research, legal review) | Pro, Non-Think or High | Pro’s 1M context is the headline feature; MRCR 1M 83.5 vs Flash 78.7 matters at depth | $0.10–1.80 per 100K-input query | Opus-4.6 still wins on MRCR (92.9) — if recall fidelity > cost, pay for Opus |
| Code review bot (PR diff review at scale) | Flash, Non-Think | SWE-Verified Resolved at Flash-Max 79.0 vs Pro-Max 80.6 — Flash gets 99% of the win at 12× cheaper output | ~$0.01–0.03 per PR | Won’t catch every subtle race condition Pro-Max would |
| Batch translation / summarisation | Flash, Non-Think | Knowledge breadth not needed; throughput and unit cost dominate | $0.40 per 1M output | Quality on niche-language pairs may degrade vs Pro |
| Customer-support triage (classifier + drafter) | Flash, Non-Think | TTFT < 500ms is the user-perceived UX; quality is sufficient for first-pass triage | ~$0.002 per ticket | Edge cases get escalated to a human, not to Pro |
| RAG replacement (drop your retrieval layer, put the corpus in context) | Pro, Non-Think | At up to ~200K context, V4-Pro’s flat $1.74/$3.48 beats Gemini’s >200K rates and is cheaper than running a vector DB + reranker | $0.20–1.80 per query | Real RAG still wins for very large corpuses (»1M tokens) where you need pre-filtering |
| Reasoning copilot (math, theorem-proving, hard logic) | Pro Max | The only V4 mode that matches frontier-proprietary reasoning; Putnam-2025 120/120, Codeforces 3206 | ~$0.01–0.10 per problem (high token count from CoT) | Cost compounds quickly with chain-of-thought — meter aggressively |
Cross-pattern recommendation: most production deployments use two model IDs, not one — Flash for the hot path, Pro for an escalation lane keyed to a difficulty heuristic. The router pattern earlier in this section makes that mechanically simple. The trap to avoid: standardising on Pro everywhere when 80% of traffic doesn’t need it (you’re paying 12× for the easy turns) or on Flash everywhere when the long tail genuinely needs Pro’s knowledge breadth.
Base URL & compatibility
DeepSeek’s API is drop-in compatible with two standards:
- OpenAI ChatCompletions —
https://api.deepseek.comas thebase_url, OpenAI SDK works unchanged. - Anthropic Messages — same host, Anthropic-style endpoint.
To migrate from V3, callers keep their existing base_url and only swap the model field.
Source: DeepSeek API Docs — V4 Preview Release.
Model IDs
| Model ID | Model | Default mode |
|---|---|---|
deepseek-v4-pro |
V4-Pro | Hybrid Thinking / Non-Thinking |
deepseek-v4-flash |
V4-Flash | Hybrid Thinking / Non-Thinking |
deepseek-chat (legacy) |
Routes to V4-Flash, Non-Thinking | — |
deepseek-reasoner (legacy) |
Routes to V4-Flash, Thinking | — |
Legacy IDs are scheduled for retirement after 2026-07-24, 15:59 UTC. Migrate to the explicit V4 IDs.
Authentication
export DEEPSEEK_API_KEY="sk-..."
All requests must include Authorization: Bearer $DEEPSEEK_API_KEY.
Quick examples
curl
curl https://api.deepseek.com/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-v4-pro",
"messages": [
{"role": "user", "content": "Explain DeepSeek Sparse Attention in one paragraph."}
]
}'
Python (OpenAI SDK)
from openai import OpenAI
client = OpenAI(
api_key=os.environ["DEEPSEEK_API_KEY"],
base_url="https://api.deepseek.com",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "Summarize the V4 announcement in 3 bullets."}
],
)
print(resp.choices[0].message.content)
Streaming
Set stream=True; the response is a Server-Sent Events stream of deltas, identical to OpenAI’s contract.
stream = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "Count to 5 slowly."}],
stream=True,
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Thinking mode (reasoning)
V4 unifies V3’s split between chat and reasoner. Thinking is opt-in per request via a model parameter; the reasoning trace is exposed as choices[].message.reasoning_content (compatible with V3’s deepseek-reasoner shape).
Exact parameter name (
thinking: truevs.mode: "thinking") TBD — to be verified against the official API reference next iteration.
JSON mode
DeepSeek V4 supports OpenAI-style JSON mode via response_format. Two requirements DeepSeek’s docs flag explicitly:
- The system or user prompt must include the word
"json"(case-insensitive) and ideally a small example of the desired shape — without it the model may return prose. - Set
max_tokensgenerously to avoid mid-string truncation.
from openai import OpenAI
import json, os
client = OpenAI(
api_key=os.environ["DEEPSEEK_API_KEY"],
base_url="https://api.deepseek.com",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system",
"content": "You output a JSON object with keys 'capital' (string) "
"and 'population_millions' (number). Example: "
'{"capital": "Paris", "population_millions": 2.1}'},
{"role": "user", "content": "Country: Japan"},
],
response_format={"type": "json_object"},
max_tokens=256,
)
data = json.loads(resp.choices[0].message.content)
print(data["capital"], data["population_millions"])
DeepSeek’s docs also note a known issue: the API may occasionally return empty content in JSON mode — wrap the parse in a try/except and retry.
Source: DeepSeek API Docs — JSON Mode.
Function calling / tool use
V4 supports OpenAI-compatible function calling via the tools parameter. A strict mode is available against the beta endpoint (https://api.deepseek.com/beta) that enforces the JSON schema.
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current temperature for a city.",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City name"},
"unit": {"type": "string", "enum": ["c", "f"]},
},
"required": ["location"],
"additionalProperties": False,
},
"strict": True, # requires beta base_url
},
}
]
messages = [{"role": "user", "content": "What's the weather in Hangzhou?"}]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
tools=tools,
)
tool_call = resp.choices[0].message.tool_calls[0]
# tool_call.function.name == "get_weather"
# tool_call.function.arguments == '{"location": "Hangzhou", "unit": "c"}'
# Round-trip: append the assistant message + tool result, then call again.
messages.append(resp.choices[0].message)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps({"temperature_c": 18, "condition": "cloudy"}),
})
final = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
tools=tools,
)
print(final.choices[0].message.content)
Strict-mode constraints (when using the beta endpoint with strict: true):
- Every property in every
objectschema must be in therequiredlist. additionalProperties: falseis required at every object level.- Supported types:
object,string,number,integer,boolean,array,enum,anyOf,$ref/$defs.
The official docs do not yet confirm parallel tool calls or streaming-with-tool-calls compatibility for V4 specifically — to be verified against an end-to-end test.
Source: DeepSeek API Docs — Function Calling.
Pricing (USD per 1M tokens)
| Model | Input — cache hit | Input — cache miss | Output |
|---|---|---|---|
| V4-Pro | $0.145 | $1.74 | $3.48 |
| V4-Flash | $0.028 | $0.14 | $0.28 |
Cache pricing applies to context caching (DeepSeek’s automatic prefix-cache feature).
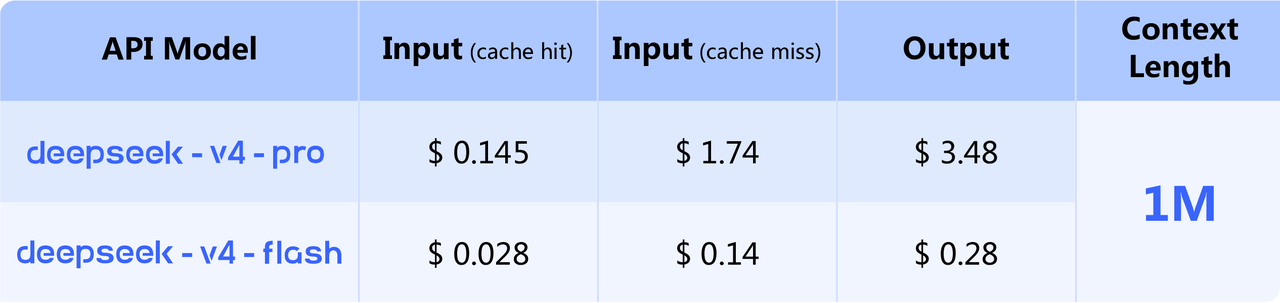 Official DeepSeek V4 pricing card. Source: api-docs.deepseek.com.
Official DeepSeek V4 pricing card. Source: api-docs.deepseek.com.
Source: DeepSeek API Docs — Pricing, DevTk — V4 API Pricing.
Alternative API providers — where else to call V4
If api.deepseek.com isn’t a procurement option (some enterprises can’t issue PRC payments, others need unified billing across multiple model vendors), V4 is available via several aggregators and inference providers within days of release:
| Provider | V4-Pro | V4-Flash | Notes |
|---|---|---|---|
| DeepSeek (direct) | ✅ | ✅ | Canonical source. PRC-jurisdiction billing. |
| OpenRouter | ✅ at deepseek/deepseek-v4-pro |
✅ at deepseek/deepseek-v4-flash |
Unified billing across many model vendors. Pricing varies by upstream provider; verify on the providers status page before committing. |
| NVIDIA NIM | ✅ at deepseek-ai/deepseek-v4-pro |
✅ at deepseek-ai/deepseek-v4-flash |
Day-0 launch. Deployable NGC container for self-hosted Blackwell deployments. NVIDIA also offers a hosted endpoint. |
| DeepInfra | ✅ | (likely) | Per-token serverless inference, US-jurisdiction billing. |
| Together AI / Fireworks / Anyscale | (announced) | (announced) | Search results indicate availability but no confirmed catalogue listings as of 2026-04-27. |
OpenRouter caveat: at the time of writing, OpenRouter advertised V4-Pro at significantly below the direct-DeepSeek rate (around $0.435 in / $0.87 out). That number is likely either a specific upstream provider’s price (DeepInfra, Together, etc., which can subsidise to win volume) or includes effective-pricing assumptions like prompt caching. Treat OpenRouter’s headline number as variable; check the providers status page for the routed rate at request time. Direct-DeepSeek pricing ($1.74 / $3.48) is the contractually stable baseline.
Self-hosting via NIM: NVIDIA published a launch-day build-with-DeepSeek-V4 walkthrough covering Blackwell-accelerated inference.
NIM’s V4-Pro reference page lists hardware support spanning three GPU generations, not just Blackwell:
| Generation | SKUs supported |
|---|---|
| NVIDIA Ampere | A100 |
| NVIDIA Hopper | H100, H200 |
| NVIDIA Blackwell | B200 |
So Blackwell delivers the FP4-tensor-core speedups V4 was QAT-trained for, but the NIM container will still serve on Hopper / Ampere clusters — the win is just smaller. License: NVIDIA Open Model Agreement with MIT licensing for the model itself.
The NIM page does not publish per-GPU throughput (tokens/second/GPU), HBM requirements, or per-request token limits beyond the 1M context window. For sizing, you’ll need NVIDIA’s solution-architecture guides or a benchmark on your specific cluster.
For local single-server deployment (no cluster), V4-Flash is the realistic target; see the community quantisations section in the news page.
Cross-vendor pricing (USD per 1M tokens, mainline tier, no caching)
| Model | Input | Output | Cached input | Source |
|---|---|---|---|---|
| DeepSeek V4-Flash | $0.14 | $0.28 | $0.028 | api-docs.deepseek.com |
| DeepSeek V4-Pro | $1.74 | $3.48 | $0.145 | api-docs.deepseek.com |
| OpenAI GPT-5.4 | $2.50 | $15.00 | $1.25 | openai.com/api/pricing |
| OpenAI GPT-5.4 (>272K context) | $5.00 | $15.00 | — | openai.com |
| OpenAI GPT-5.5 | $5.00 | $30.00 | — | apidog.com |
| OpenAI GPT-5.5-Pro | $30.00 | $180.00 | — | apidog.com |
| Anthropic Claude Opus 4.7 | $5.00 | $25.00 | $0.50 | platform.claude.com/docs/en/about-claude/pricing |
| Google Gemini 3.1 Pro (≤200K context) | $2.00 | $12.00 | $0.20 | ai.google.dev/gemini-api/docs/pricing |
| Google Gemini 3.1 Pro (>200K context) | $4.00 | $18.00 | — | ai.google.dev/gemini-api/docs/pricing |
Multipliers (V4-Pro = 1×):
- Output: V4-Pro is 7.2× cheaper than Opus 4.7, 4.3× cheaper than GPT-5.4, 8.6× cheaper than GPT-5.5, 3.4× cheaper than Gemini 3.1 Pro.
- Input (uncached): V4-Pro is 2.9× cheaper than Opus 4.7, 1.4× cheaper than GPT-5.4, slightly more expensive than Gemini under 200K (1.74 vs 2.00 — actually V4-Pro is cheaper at the standard tier).
- Cached input: V4-Pro at $0.145 is 3.4× cheaper than Opus and 1.4× cheaper than Gemini 3.1 Pro’s cached input ($0.20).
- Long-context tipping point: Gemini doubles its input rate above 200K. V4-Pro charges the same $1.74 / 1M for the entire 1M-token window — making V4-Pro the cheapest frontier option once you cross 200K context.
V4-Flash widens these gaps by another order of magnitude — Flash output at $0.28 / 1M is 89× cheaper than Opus 4.7 output. The headline tradeoff is V4-Flash’s smaller capability budget; see Benchmarks Table 7 for what Flash-Max can and can’t match.
Cost calculator
Drop in your token budget; the function returns dollar costs across V4-Pro and V4-Flash with optional cache-hit fraction.
def deepseek_v4_cost(input_tokens: int, output_tokens: int, cache_hit_fraction: float = 0.0):
"""
Returns a dict of USD costs for V4-Pro and V4-Flash given a workload.
Pricing per the official api-docs.deepseek.com (2026-04-26).
"""
rates = {
"v4-pro": {"in_miss": 1.74, "in_hit": 0.145, "out": 3.48},
"v4-flash": {"in_miss": 0.14, "in_hit": 0.028, "out": 0.28},
}
out = {}
for name, r in rates.items():
in_hit = input_tokens * cache_hit_fraction
in_miss = input_tokens * (1 - cache_hit_fraction)
cost = (in_hit * r["in_hit"] + in_miss * r["in_miss"] + output_tokens * r["out"]) / 1_000_000
out[name] = round(cost, 4)
return out
# Example: a 100K-context agent loop returning 5K of output, 70% prefix-cached
deepseek_v4_cost(100_000, 5_000, cache_hit_fraction=0.7)
# {'v4-pro': 0.0758, 'v4-flash': 0.0066}
Worked examples:
| Workload | V4-Flash | V4-Pro | Opus 4.7 (uncached) |
|---|---|---|---|
| 1K in + 1K out (single chat turn) | $0.0004 | $0.0052 | $0.030 |
| 100K in + 5K out (agent step, no cache) | $0.0154 | $0.1914 | $0.625 |
| 100K in + 5K out, 70% prefix-cached | $0.0066 | $0.0758 | ~$0.31 |
| 1M in + 10K out (full long-context query) | $0.143 | $1.775 | $5.250 |
| 32M in + 1M out / month (heavy agent fleet) | $4.762 | $59.24 | $185 |
The headline take: V4-Flash is the budget weapon; V4-Pro is the frontier-quality at frontier-minus-half-an-order-of-magnitude price. With prefix caching, V4-Pro’s effective input cost approaches Flash territory.
Rate limits & regional availability (TBD)
DeepSeek’s preview post does not enumerate rate limits or regional restrictions. Will be confirmed against the API reference next iteration.
Still open against primary sources
DeepSeek hasn’t published authoritative answers to these yet; we’ll update when they do.
- Thinking-mode parameter shape. The exact request key (
thinking: truevsmode: "thinking"vs something else) isn’t documented in the official API reference. The Python examples on this page mark it as TBD; verify against an end-to-end call before standardising on a name in production code. - Rate limits and per-region availability. The DeepSeek API docs don’t enumerate per-tier rate limits or regional restrictions. Production deployments should derive these empirically per provider and tier.