DeepSeek V4
Technical Details
Architecture, training setup, and model variants — backed by the official `config.json` and tech report.
In one paragraph · Last verified 2026-04-27
V4-Pro reuses V3’s exact backbone shape (hidden 7168, 61 layers, 128 attention heads). The 671B → 1.6T parameter growth comes entirely from MoE expansion (256 → 384 routed experts, expert-FFN width 2048 → 3072). The two genuinely new architectural pieces are CSA + HCA hybrid attention (m=4 and m′=128 compression ratios interleaved per layer, with DSA from V3.2 doing top-1024 selection inside CSA) and mHC residuals (Birkhoff-polytope projection via 20 Sinkhorn–Knopp iterations to restore identity mapping at scale). Quantisation is mixed: FP8 base + FP4 routed experts + FP4 indexer attention, all QAT’d. Trained on 33T tokens (Pro) / 32T tokens (Flash) with the Muon optimiser. Post-training replaces V3.2’s mixed-RL stage with On-Policy Distillation of GRPO-trained specialists. Training stability is held together by Anticipatory Routing and SwiGLU Clamping — DeepSeek explicitly admits the theoretical underpinnings are open questions (Section 4.2.3).
On this page
- Model variants — config-backed numbers
- Architecture overview
- V3 → V3.2 → V4 architectural diff
- Architecture lineage
- Hybrid attention: CSA + HCA (with DSA inside CSA)
- mHC — config-confirmed
- Quantisation — FP8 base + FP4 routed experts + FP4 indexer
- Context extension — YaRN
- Multi-token prediction & hash routing
- Training stability — what’s holding it together
- Tokenizer
- Scoring & balancing
- Hardware & deployment
- Training — from the tech report
- Architecture decisions journal
- 1. Hybrid CSA + HCA, not pure DSA
- 2. mHC instead of vanilla residual stream
- 3. FP4 for routed experts and indexer, FP8 elsewhere
- 4. OPD (On-Policy Distillation) replacing the mixed-RL stage
- 5. Reuse V3’s exact backbone shape (7168 / 61 / 128)
- 6. Hash routing as a load-balance backstop
- 7. YaRN context extension instead of native 1M training
Model variants — config-backed numbers
All values below are verbatim from the official config.json at:
huggingface.co/deepseek-ai/DeepSeek-V4-Pro/.../config.json(mirrored locally atdeepseek-v4/configs/v4-pro-config.json)huggingface.co/deepseek-ai/DeepSeek-V4-Flash/.../config.json(mirrored locally atdeepseek-v4/configs/v4-flash-config.json)
| Field | V4-Pro | V4-Flash |
|---|---|---|
hidden_size |
7168 | 4096 |
num_hidden_layers |
61 | 43 |
num_attention_heads |
128 | 64 |
num_key_value_heads |
1 (MLA) | 1 (MLA) |
head_dim |
512 | 512 |
qk_rope_head_dim |
64 | 64 |
q_lora_rank |
1536 | 1024 |
o_lora_rank |
1024 | 1024 |
o_groups |
16 | 8 |
n_routed_experts |
384 | 256 |
n_shared_experts |
1 | 1 |
num_experts_per_tok |
6 | 6 |
moe_intermediate_size |
3072 | 2048 |
routed_scaling_factor |
2.5 | 1.5 |
topk_method |
noaux_tc |
noaux_tc |
scoring_func |
sqrtsoftplus |
sqrtsoftplus |
vocab_size |
129,280 | 129,280 |
max_position_embeddings |
1,048,576 (= 2²⁰) | 1,048,576 |
num_nextn_predict_layers |
1 (MTP) | 1 (MTP) |
num_hash_layers |
3 | 3 |
sliding_window |
128 | 128 |
hidden_act |
silu |
silu |
torch_dtype |
bfloat16 |
bfloat16 |
architectures |
DeepseekV4ForCausalLM |
DeepseekV4ForCausalLM |
Headline parameter splits (from the official announcement, not config-derivable):
| Total params | Active params | |
|---|---|---|
| V4-Pro | 1.6T | 49B |
| V4-Flash | 284B | 13B |
Routing: 6 routed experts + 1 shared expert active per token. Pro picks 6 from a pool of 384 (1.6% sparsity); Flash picks 6 from 256 (2.3% sparsity). topk_method: noaux_tc confirms the auxiliary-loss-free balancing that DeepSeek introduced in V3 is retained.
Sources: V4-Pro config.json, V4-Flash config.json, DeepSeek API Docs.
Architecture overview
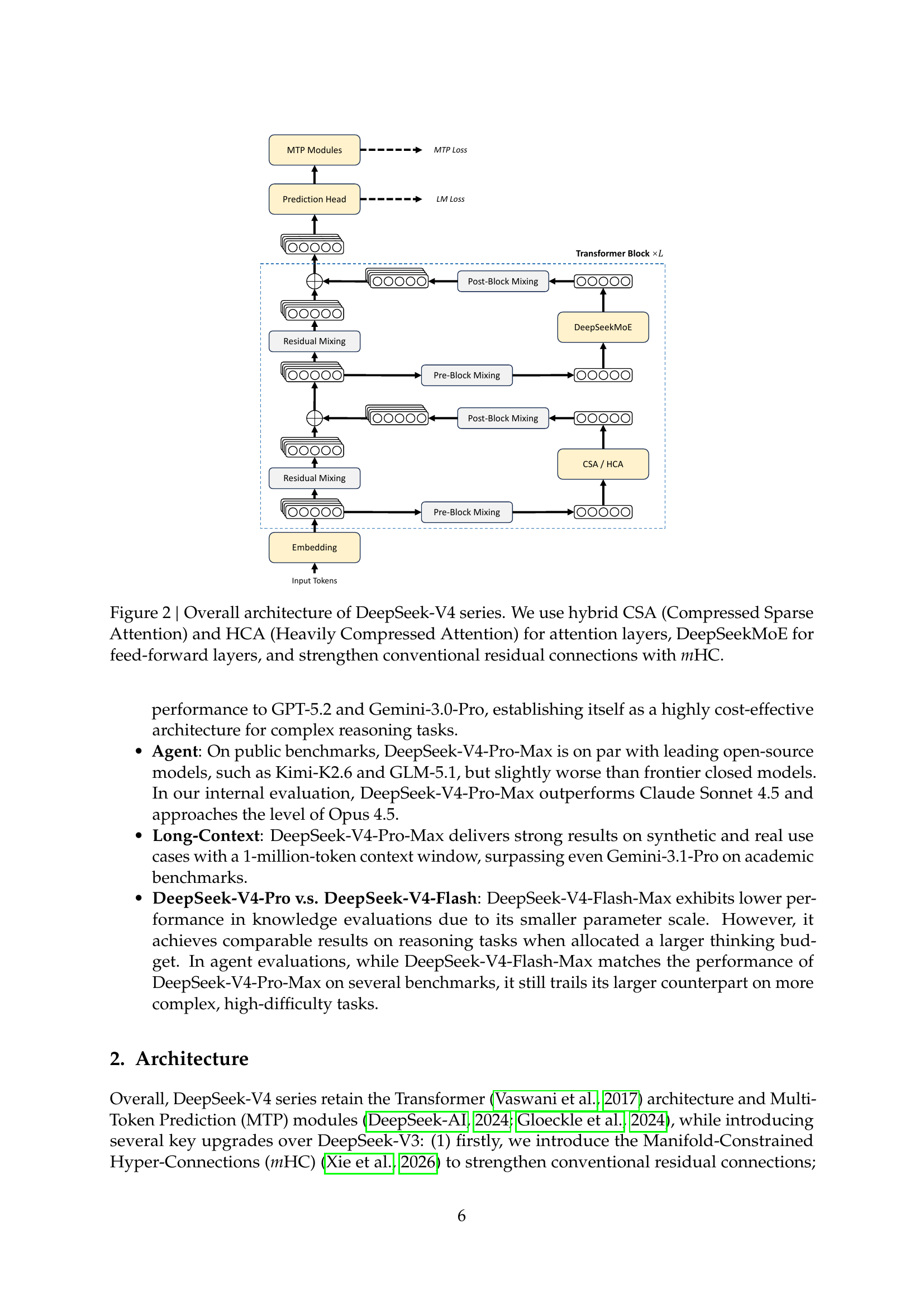 Overall architecture of DeepSeek-V4 series. Hybrid CSA + HCA attention layers, DeepSeekMoE for FFNs, and Manifold-Constrained Hyper-Connections (mHC) replacing the residual stream. Source: tech report Figure 2 (page 6).
Overall architecture of DeepSeek-V4 series. Hybrid CSA + HCA attention layers, DeepSeekMoE for FFNs, and Manifold-Constrained Hyper-Connections (mHC) replacing the residual stream. Source: tech report Figure 2 (page 6).
V3 → V3.2 → V4 architectural diff
What actually changed across the last three DeepSeek generations:
| Component | V3 (2024-12) | V3.2 (2025-12) | V4 (2026-04) |
|---|---|---|---|
| Total / active params | 671B / 37B | 671B / 37B | Pro: 1.6T / 49B · Flash: 284B / 13B |
| Context window | 160K (max_position_embeddings: 163840, YaRN factor 40) |
128K | 1,048,576 (1M, default; YaRN factor 16) |
| Hidden size · layers · heads | 7168 · 61 · 128 | 7168 · 61 · 128 | Pro: 7168 · 61 · 128 (same shape as V3) · Flash: 4096 · 43 · 64 |
| Attention | MLA (kv_lora_rank: 512, num_key_value_heads: 128) |
MLA + DSA (new — lightning indexer + top-k) | MLA + CSA + HCA (hybrid), DSA inside CSA · num_key_value_heads: 1 |
| MoE | DeepSeekMoE (256 routed + 1 shared, top-8, moe_intermediate_size: 2048); first 3 layers dense |
DeepSeekMoE (continued from V3) | DeepSeekMoE (Pro: 384 routed, top-6, moe_intermediate_size: 3072 · Flash: 256 routed, top-6, 2048) |
| Routing | Auxiliary-loss-free (noaux_tc) |
noaux_tc |
noaux_tc + Hash routing (3 hash layers) |
| Residual stream | Standard residual | Standard residual | mHC (new) — Birkhoff-Polytope projection via Sinkhorn–Knopp |
| Optimiser | AdamW | AdamW | Muon (new) |
| Quantisation | FP8 e4m3 (block 128×128) | FP8 (refined) | FP8 base + FP4 routed experts + FP4 indexer (QAT) |
| Training tokens | 14.8T (from-scratch) | 14.8T + 943.7B continued-pre-training (DSA stage) | Flash 32T · Pro 33T (from-scratch) |
| Post-training | SFT + mixed RL | Specialist distillation + mixed RL via GRPO (reasoning + agent + alignment merged into one RL stage) | OPD (On-Policy Distillation) (replaces V3.2’s mixed-RL stage) + GRPO specialists |
| Post-training compute | — | >10% of pre-training cost | (unspecified, comparable scale) |
| Multi-token prediction | Yes (1 layer) | Yes | Yes (1 layer) |
| Training-stability tricks | — | — | Anticipatory Routing, SwiGLU Clamping |
| Reasoning modes | None | chat / reasoner (separate models) · V3.2-Speciale for max compute |
Hybrid Thinking / Non-Thinking + reasoning-effort scaling (8K / 128K / 384K) |
| Open weights license | MIT | MIT | MIT |
Notable observation: V4-Pro reuses V3’s hidden size, layer count, and head count exactly (7168 · 61 · 128). The growth from 671B → 1.6T total parameters comes entirely from the MoE expansion — 256 → 384 routed experts (1.5×) and an moe_intermediate_size increase from 2048 → 3072. V4-Pro is V3’s backbone with a wider expert pool, hybrid CSA/HCA attention bolted on, mHC residuals, and a much longer YaRN-scaled context.
The V3 → V4 jump is genuinely large; the V3.2 → V4 jump is mostly scale (1.6T vs 671B), context (1M vs 160K → 128K → 1M), and the CSA/HCA hybrid attention that makes 1M context cheap. Note that V3.2 itself was a continued-pretraining refresh on top of V3 (only ~946B additional tokens to introduce DSA), whereas V4 is a from-scratch run on 32–33T tokens — so the parameter-count change comes with a fresh data budget.
Sources: DeepSeek-V3 tech report (arXiv:2412.19437), DeepSeek-V3.2 paper (arXiv:2512.02556), DeepSeek_V4.pdf, model config.json files.
Architecture lineage
V4 builds on three publicly documented DeepSeek innovations, each with a primary-source paper:
| Component | Paper | arXiv | Posted |
|---|---|---|---|
| DeepSeek Sparse Attention (DSA) | DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models | arXiv:2512.02556 | December 2025 |
| Manifold-Constrained Hyper-Connections (mHC) | mHC: Manifold-Constrained Hyper-Connections | arXiv:2512.24880 | 2025-12-31 (v1), 2026-01-05 (v2) |
| DeepSeekMoE (continued from V3 with minor adjustments) | DeepSeekMoE / DeepSeek-V3 series | (V3 series) | — |
mHC was co-authored by 20 DeepSeek researchers, with Wenfeng Liang as last author — a strong signal it became load-bearing for V4. The config confirms its presence: see the hc_* fields below.
The official DeepSeek_V4.pdf tech report (huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf, 4.5 MB) has been ingested in full and is the source for most numbers on this page.
Hybrid attention: CSA + HCA (with DSA inside CSA)
The official DeepSeek_V4.pdf tech report names V4’s attention design “Hybrid Attention with CSA and HCA” (Section 2.3). Earlier coverage that called this “Compress-4-Attention / Compress-128-Attention” was a third-party renaming; the 4 and 128 in the config’s compress_ratios array are the per-layer compression ratios (m and m′), not layer names.
The two attention variants
From the tech report (verbatim):
“we design two efficient attention architectures — Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) — and employ their interleaved hybrid configuration… CSA integrates both compression and sparse attention strategies: it first compresses the Key-Value (KV) cache of every 𝑚 tokens into one entry, and then applies DeepSeek Sparse Attention (DSA) where each query token attends to only 𝑘 compressed KV entries. HCA aims for extreme compression by consolidating the KV cache of every 𝑚′ (≫ 𝑚) tokens into a single entry.”
So:
- CSA: compress every m=4 tokens into one entry → run DSA (lightning indexer + top-k selection from V3.2) over the compressed entries → MQA core attention. Plus a sliding window of recent uncompressed tokens for local fidelity.
- HCA: aggressively compress every m′=128 tokens into one entry → MQA over compressed entries (no further DSA selection needed, since the count is already small). Same sliding-window addition.
- Hybrid: layers alternate CSA and HCA across the model —
compress_ratiosencodes the schedule.
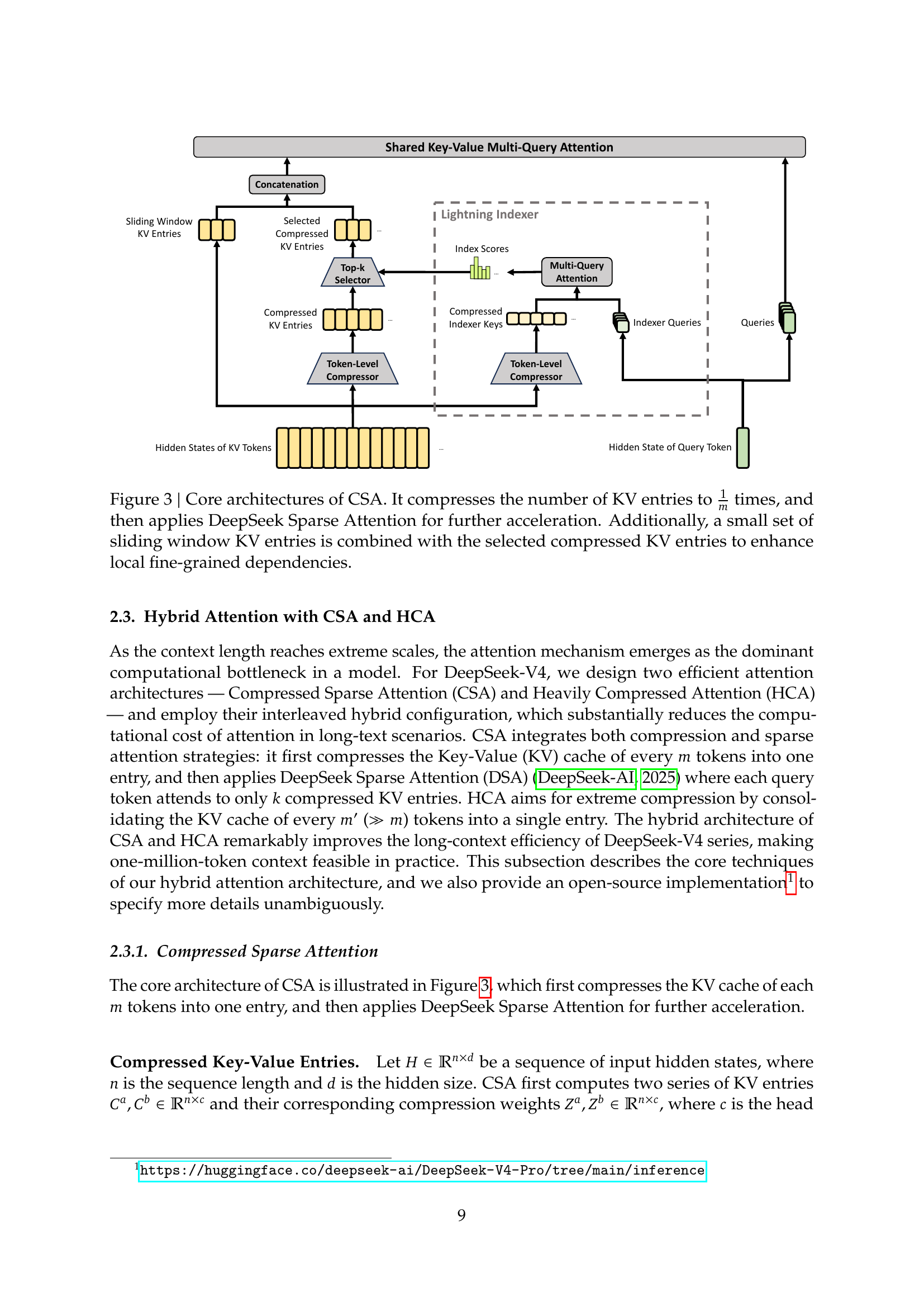 Core architecture of CSA. Compresses every m KV entries into one, then applies DSA top-k selection. A small sliding window of recent uncompressed KV entries is concatenated to enhance local fine-grained dependencies. Source: tech report Figure 3 (page 9).
Core architecture of CSA. Compresses every m KV entries into one, then applies DSA top-k selection. A small sliding window of recent uncompressed KV entries is concatenated to enhance local fine-grained dependencies. Source: tech report Figure 3 (page 9).
 Core architecture of HCA. Heavy compression — every m′ (≫ m) tokens become one entry — feeding shared-key-value MQA. The same sliding window is appended. Source: tech report Figure 4 (page 11).
Core architecture of HCA. Heavy compression — every m′ (≫ m) tokens become one entry — feeding shared-key-value MQA. The same sliding window is appended. Source: tech report Figure 4 (page 11).
Layer-by-layer compression schedule
The compress_ratios array in config.json is the ground-truth schedule:
V4-Pro (61 layers): [128, 128, 4, 128, 4, 128, …, 4, 128, 4, 0] — two HCA layers up front, then 28 interleaved CSA/HCA pairs across the bulk, with the final layer using uncompressed full attention (0).
V4-Flash (43 layers): [0, 0, 4, 128, 4, 128, …, 4, 128, 4, 0] — two uncompressed layers up front, then 19 interleaved CSA/HCA pairs, ending with a final uncompressed layer.
That is, both models bookend the stack with full-attention layers and use the hybrid CSA/HCA pattern through the bulk. Pro additionally puts HCA at the very front to compress aggressively before fine-tuning the representation; Flash uses dense attention there.
V4’s DSA parameters (lightning indexer, from config.json)
DSA continues to live inside CSA as the top-k selector over compressed entries. The index_* fields control it:
 The original DSA architecture as it shipped in V3.2 — the lightning indexer scores every historical key against the current query, top-k entries are selected, and core attention runs over only that subset, all instantiated under MLA. V4’s CSA wraps this same mechanism around a token-level compression step. Source: DeepSeek-V3.2 paper Figure 2 (page 4).
The original DSA architecture as it shipped in V3.2 — the lightning indexer scores every historical key against the current query, top-k entries are selected, and core attention runs over only that subset, all instantiated under MLA. V4’s CSA wraps this same mechanism around a token-level compression step. Source: DeepSeek-V3.2 paper Figure 2 (page 4).
| Field | V4-Pro | V4-Flash | What it means |
|---|---|---|---|
index_n_heads |
64 | 64 | Lightning-indexer head count |
index_head_dim |
128 | 128 | Indexer head dimension |
index_topk |
1024 | 512 | Top-k compressed entries selected per query |
compress_rope_theta |
160000 | 160000 | RoPE base for the compressed-attention path |
In V4-Pro, regardless of context length, each CSA layer only attends to the top 1024 compressed entries chosen by the indexer (top 512 in Flash). Combined with HCA’s heavy compression, this is what makes 1M context cheap.
The tech report further notes:
“attention computation within the lightning indexer is performed in FP4 precision, while FP8 is applied to the remaining dimensions” — meaning DSA’s hot path is FP4 even though the rest of attention is FP8.
Reported efficiency
At a 1M-token context, the tech report states:
| Model | vs V3.2 single-token FLOPs | vs V3.2 KV cache |
|---|---|---|
| V4-Pro | ~27% (3.7× lower) | ~10% (9.5× smaller) |
| V4-Flash | ~10% (9.8× lower) | ~7% (13.7× smaller) |
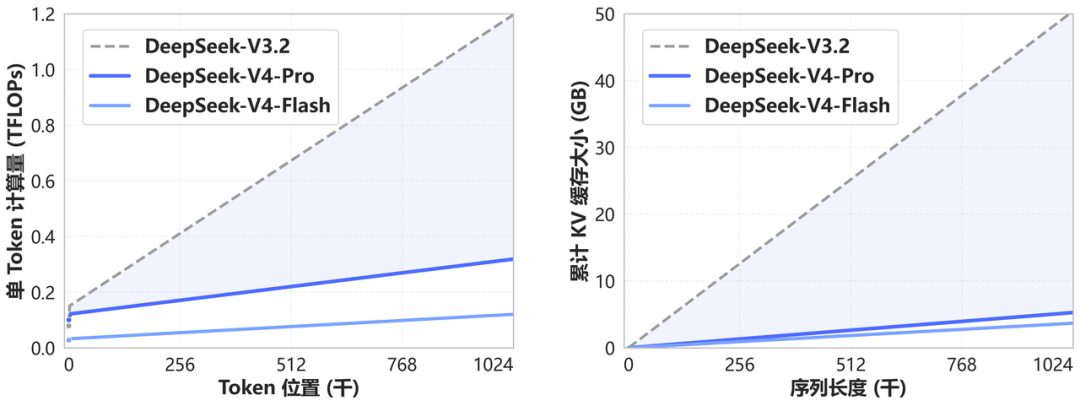 V4-Pro vs V3.2 — single-token inference FLOPs and KV cache at 1M context. Source: api-docs.deepseek.com.
V4-Pro vs V3.2 — single-token inference FLOPs and KV cache at 1M context. Source: api-docs.deepseek.com.
MLA backbone
Both models use a single KV head (num_key_value_heads: 1) — the hallmark of DeepSeek’s Multi-head Latent Attention, where keys and values live in a low-rank latent space and are reconstructed on demand. The q_lora_rank and o_lora_rank fields confirm low-rank Q and output projections (1536 / 1024 in Pro, 1024 / 1024 in Flash).
After CSA’s top-k selection, the core attention runs as Multi-Query Attention (MQA) over the compressed entries, with a grouped output projection (o_groups = 16 in Pro, 8 in Flash) to keep the projection FLOPs manageable when the head count is large.
Reference implementation
DeepSeek published the inference reference code alongside the model: huggingface.co/deepseek-ai/DeepSeek-V4-Pro/tree/main/inference.
mHC — config-confirmed
Lineage: Hyper-Connections (HC) → mHC
DeepSeek’s mHC paper (arXiv:2512.24880) is an extension of the upstream Hyper-Connections paper from 2024:
- Hyper-Connections (HC) — arXiv:2409.19606, Defa Zhu et al., submitted September 2024, latest revision March 2025.
“Hyper-connections … addresses common drawbacks observed in residual connection variants, such as the seesaw effect between gradient vanishing and representation collapse. Theoretically, hyper-connections allow the network to adjust the strength of connections between features at different depths and dynamically rearrange layers.” — HC abstract
HC introduced the idea of widening the residual stream into multiple hyper connections so the network can learn to dynamically rebalance depth-wise information flow. The authors are Defa Zhu, Hongzhi Huang, Zihao Huang, Yutao Zeng, Yunyao Mao, Banggu Wu, Qiyang Min, and Xun Zhou.
- mHC — DeepSeek’s contribution: HC sacrifices the identity-mapping property that vanilla residuals provide, which causes training instability at scale. mHC restores identity mapping by projecting HC’s mixing matrices onto the Birkhoff polytope (the manifold of doubly-stochastic matrices) via the Sinkhorn–Knopp algorithm, paying ~6–7% extra training overhead in exchange for stable scaling. Wenfeng Liang appears as last author, signalling DeepSeek-leadership ownership.
So mHC is HC’s elegance with a stability fix. V4 is the first production model to ship the technique at scale.
Config-confirmed parameters
The mHC paper’s specifics turn up directly in config.json:
| Field | V4-Pro | V4-Flash | Maps to |
|---|---|---|---|
hc_mult |
4 | 4 | Hyper-connection multiplier (residual-stream width factor) |
hc_sinkhorn_iters |
20 | 20 | Iterations of the Sinkhorn–Knopp algorithm enforcing the Birkhoff-Polytope constraint |
hc_eps |
1e-06 | 1e-06 | Numerical tolerance for the Sinkhorn projection |
This is the cleanest possible confirmation that mHC, as described in arXiv:2512.24880, is the operational residual-stream design across all V4 layers. The paper described the mathematical framework (project onto Birkhoff Polytope via Sinkhorn–Knopp); the config tells you that the implementation runs the projection for 20 iterations every step.
Quantisation — FP8 base + FP4 routed experts + FP4 indexer
The full quantisation story (Section 3.4 of the tech report and the quantization_config block in config.json):
- Base weights: FP8 e4m3 with a UE8M0-formatted scale and 128×128 block quantisation — the format DeepSeek pioneered for V3 and refined for V3.2.
- Routed expert weights: FP4 (quantisation-aware-trained). Section 3.4 is titled “FP4 Quantization-Aware Training” and explicitly notes “for DeepSeek-V4 series, the routed expert parameters utilize FP4 precision.”
- Lightning-indexer attention: FP4 computation.
- Other dimensions (e.g., the RoPE-applied query/key dimensions): FP8.
"quantization_config": {
"activation_scheme": "dynamic",
"fmt": "e4m3",
"quant_method": "fp8",
"scale_fmt": "ue8m0",
"weight_block_size": [128, 128]
}
So both earlier framings were partly right: the open-weight checkpoint’s headline format is FP8, but routed experts and the indexer are FP4, both trained that way (QAT) — not post-training quantised. The tech report flags that FP4 × FP8 peaks are equal to FP8 × FP8 on current hardware, so the FP4 win is mostly memory and bandwidth rather than compute.
Context extension — YaRN
V4 reaches 1M context via YaRN scaling on top of a 64K base:
"rope_scaling": {
"beta_fast": 32,
"beta_slow": 1,
"factor": 16,
"original_max_position_embeddings": 65536,
"type": "yarn"
}
64K × 16 = ~1M. This is a continuation of DeepSeek’s V2/V3 long-context recipe rather than a fresh scaling approach.
Multi-token prediction & hash routing
num_nextn_predict_layers: 1 confirms V4 keeps the multi-token prediction training objective from V3.
num_hash_layers: 3 indexes the Hash routing strategy described in Section 2.1 of the tech report (citing Roller et al., 2021): a fixed-routing fallback applied alongside DeepSeekMoE’s learned routing — used to guarantee load balance without aux losses, complementing topk_method: noaux_tc.
Training stability — what’s holding it together
Section 4.2.3 of the tech report is unusually candid: training trillion-parameter MoE models is unstable, and DeepSeek discovered two empirical fixes whose theoretical underpinnings they don’t fully understand.
Anticipatory Routing
“We found that decoupling the synchronous updates of the backbone network and the routing network significantly improves training stability.” — Section 4.2.3
At step t, the backbone uses current parameters θ_t, but the routing indices are computed from historical parameters θ_{t−Δt}. To avoid loading the model twice, DeepSeek pre-fetches the data for step t at step t−Δt and “anticipatorily” caches the routing indices.
- Wall-clock overhead: ~20%.
- Triggered dynamically: a loss-spike detector activates Anticipatory Routing only when needed; the system reverts to standard training afterward.
- Why it works: open question. DeepSeek explicitly flags this as a future research target.
SwiGLU Clamping
The swiglu_limit: 10.0 field in config.json is the operational expression of this technique:
“We clamped the linear component of SwiGLU to the range of [−10, 10], while capping the upper bound of the gate component at 10.” — Section 4.2.3
DeepSeek correlates outlier activations with MoE-router-driven loss spikes; clamping eliminates the outliers, which eliminates the spikes. As with Anticipatory Routing, the empirical link is documented; the principled reason is not.
This honesty is unusual in frontier-model tech reports and is worth treating as a leading indicator of where future-V5 architectural simplification will land.
Tokenizer
From tokenizer_config.json (mirrored at deepseek-v4/configs/v4-pro-tokenizer-config.json):
vocab_size: 129,280 (within rounding of V3’s 128K BPE tokenizer).tokenizer_class:PreTrainedTokenizerFast(BPE, Rust implementation).model_max_length: 1,048,576 — matchesmax_position_embeddings, so the tokenizer doesn’t impose a tighter limit than the model.- BOS token:
<|begin▁of▁sentence|>(full-width pipe|and a special triangle character — same as V3, confirming continuity). - EOS token:
<|end▁of▁sentence|>(also doubles aspad_token). add_bos_token: false, add_eos_token: false— callers manage BOS/EOS explicitly.unk_token: null— BPE never emits<unk>; vocabulary covers everything.
The tech report does not flag tokenizer changes as a notable architectural difference. The BOS/EOS delimiters are byte-identical to V3, suggesting V4 reuses (or near-reuses) the V3 tokenizer.
Scoring & balancing
scoring_func: sqrtsoftplus— V3-era expert router scoring is retained.topk_method: noaux_tc— auxiliary-loss-free load balancing (DeepSeek’s V3 contribution).
Hardware & deployment
The tech report (Section 3.1) explicitly states that V4’s expert-parallelism scheme runs “on both NVIDIA GPUs and HUAWEI Ascend NPUs platforms,” with up to 1.96× speedup vs strong baselines in latency-sensitive scenarios such as RL rollouts and high-speed agent serving. This makes V4 the first DeepSeek release to claim production-ready Ascend deployment as a first-class target. Source: tech report; Fortune; LMSYS Day-0.
sliding_window: 128 is the per-CSA-and-HCA-layer uncompressed sliding window — recent tokens within this window are added to the compressed/selected KV set so the model retains fine-grained local fidelity even when most context is compressed. Confirmed in Section 2.3.2 (“we additionally produce 𝑛win uncompressed KV entries corresponding to the recent 𝑛win tokens”).
Training — from the tech report
Pre-training
- V4-Flash: pre-trained on 32T tokens.
- V4-Pro: pre-trained on 33T tokens.
- Mathematical and programming corpora remain core components.
- Optimiser: Muon (Jordan et al., 2024; Liu et al., 2025) for the majority of modules. Section 2.4 details DeepSeek’s adaptations: weight decay applied to Muon parameters, and a specific scaling technique from Liu et al. (2025).
- MTP loss weight: 0.3. Hash-routing balance threshold: 0.0001 to avoid extreme imbalance within single sequences.
Post-training
V4’s post-training pipeline largely mirrors V3.2’s, with one critical substitution: the mixed RL stage was entirely replaced by On-Policy Distillation (OPD) (tech report Section 5.1).
The pipeline:
- Specialist training — for each domain (reasoning, code, agent, instruction-following), a separate expert model is trained. Each gets supervised fine-tuning + RL via GRPO (Group Relative Policy Optimization), with hyper-params aligned with prior DeepSeek work.
- Model consolidation — the specialists are merged into a single set of weights via OPD. The student model optimises a reverse KL loss
D_KL(π_θ || π_E_i)against each specialist teacher; the tech report notes “the reverse KL loss yields more stable gradient estimates and ensures faithful distillation.” - Reasoning-effort scaling — three modes are exposed (Non-Think, High, Max) with reasoning-token context windows of 8K / 128K / 384K respectively. V4-Pro-Max is the maximum-reasoning-effort mode.
Reconciling the 49B-vs-35B figure
Tech report Table 1 confirms V4-Pro Base activates 49B params. The “~35B active” figure cited in some early third-party deep-dives was a misread; the correct primary-source number is 49B. V3.2 Base for comparison: 671B total, 37B activated.
Other infrastructure (Section 3)
-
3.1 Fine-grained communication-computation overlap in expert parallelism, with a wave-based expert scheduler — the source of the 1.96× speedup figure for RL rollouts and high-speed agent serving.
 DeepSeek-V4’s expert-parallelism scheme vs Comet (Zhang et al., 2025b). Each MoE layer is decomposed into four stages; experts are split into waves so that computation on the current wave overlaps token transfer for the next and result-sending of the previous, forming a fine-grained pipeline. Source: tech report Figure 5 (page 15).
DeepSeek-V4’s expert-parallelism scheme vs Comet (Zhang et al., 2025b). Each MoE layer is decomposed into four stages; experts are split into waves so that computation on the current wave overlaps token transfer for the next and result-sending of the previous, forming a fine-grained pipeline. Source: tech report Figure 5 (page 15). - 3.2 TileLang — DeepSeek’s flexible kernel DSL for the new attention paths.
- 3.3 Batch-invariant deterministic kernel libraries — for reproducible inference.
- 3.5.3 Contextual parallelism for long-context attention — the parallelism strategy that lets the 1M-context training and inference fit on cluster hardware.
-
3.6 KV cache structure & on-disk storage — V4 uses a customised KV cache layout with on-disk storage support to handle the 1M-context regime under realistic memory budgets.
 V4’s customised KV cache layout. The cache is organised into a structure that matches the CSA/HCA hybrid attention pattern, with on-disk storage support for the long tail. Source: tech report Figure 6 (page 23).
V4’s customised KV cache layout. The cache is organised into a structure that matches the CSA/HCA hybrid attention pattern, with on-disk storage support for the long tail. Source: tech report Figure 6 (page 23).
Architecture decisions journal
The why behind V4’s choices, distilled from the tech report and cross-referenced against V3, V3.2, and the published precursor papers. Each decision lists DeepSeek’s pick, the constraint it solves, the cost it pays, and what V5 is likely to do differently based on Section 6’s stated future directions.
1. Hybrid CSA + HCA, not pure DSA
- Choice: two interleaved attention variants — Compressed Sparse Attention (m=4) for fine-grained nearby context, Heavily Compressed Attention (m′=128) for distant context.
- Why: V3.2’s pure DSA (lightning indexer + top-k over uncompressed entries) hit a complexity floor at very long contexts. The two-scale hybrid lets each layer specialise: CSA preserves local fidelity, HCA delivers the 10× KV-cache savings that make 1M default-tier feasible.
- Cost paid: more architectural complexity (two attention paths to maintain, schedule per-layer via
compress_ratios). - V5 hint: Section 6 commits to “distill the architecture down to its most essential designs.” Expect V5 to either drop one of CSA/HCA or unify them into a single learned-compression scheme.
2. mHC instead of vanilla residual stream
- Choice: Manifold-Constrained Hyper-Connections — wider residual stream, mixing matrices projected onto the Birkhoff polytope via Sinkhorn-Knopp.
- Why: vanilla HC (the arXiv:2409.19606 precursor) widens the residual stream effectively but breaks the identity-mapping property, causing training instability at 1.6T scale. mHC restores identity mapping via the manifold projection — buying back stability at ~6–7% extra compute.
- Cost paid: 20 Sinkhorn-Knopp iterations per step (
hc_sinkhorn_iters: 20); ~6–7% training overhead. - V5 hint: Section 6 commits to studying “foundational problems on training stability.” Expect V5 to either reduce the iteration count, replace Sinkhorn with a closed-form projection, or — most interestingly — find a residual-stream design that doesn’t need post-hoc projection.
3. FP4 for routed experts and indexer, FP8 elsewhere
- Choice: mixed-precision quantisation —
routed_expertsand the lightning-indexer attention path run in FP4 (QAT); base weights, RoPE-applied dimensions, and the rest of the stack stay in FP8. - Why: routed experts dominate parameter count but are touched on a per-token basis (only ~6 of 384 active in V4-Pro). FP4 cuts their memory and bandwidth cost without hitting accuracy hard. FP8 elsewhere preserves fidelity where the entire weight matrix gets used every token.
- Cost paid: more complex inference kernels (mixed-precision tensor cores, per-tensor scale formats). The tech report’s TileLang DSL and batch-invariant deterministic kernels (Sections 3.2 and 3.3) exist partly to manage this.
- V5 hint: NVIDIA Blackwell’s FP4 × FP4 path will eventually deliver the compute wins that match the memory wins. Expect V5 to push FP4 into more of the model — possibly all weights, or specifically the lightning-indexer top-k softmax.
4. OPD (On-Policy Distillation) replacing the mixed-RL stage
- Choice: train domain specialists with GRPO; consolidate them into a single set of weights via On-Policy Distillation, not a final mixed-RL stage as in V3.2.
- Why: V3.2’s mixed-RL stage was expensive (>10% of pre-training cost) and risked catastrophic interference between domain rewards (reasoning vs alignment vs agent vs coding). Distillation is cheaper and more controllable — each specialist is independent, the consolidator is a supervised target.
- Cost paid: more pipeline machinery (specialists must be trained, evaluated, then distilled). Also raises a question DeepSeek doesn’t address: does OPD lose the exploration benefits of online RL?
- V5 hint: if OPD scales, V5 will likely make this the standard. If specific specialist domains underperform vs RL-trained baselines, V5 may go back to mixed-RL.
5. Reuse V3’s exact backbone shape (7168 / 61 / 128)
- Choice: V4-Pro keeps V3’s
hidden_size,num_hidden_layers, andnum_attention_headsexactly. The 671B → 1.6T parameter growth comes entirely from MoE expansion (256 → 384 routed experts,moe_intermediate_size2048 → 3072). - Why: training a fresh 1.6T-parameter base from random init is a multi-month, multi-million-dollar gamble. By holding the backbone constant, DeepSeek gets to recover most of V3’s training-recipe knowledge — schedules, optimiser hyper-params, kernel fusions. Risk is concentrated in the new components (CSA/HCA, mHC, FP4 QAT, Muon).
- Cost paid: model gets bigger by a path that may not be Pareto-optimal — a wider-and-shallower or deeper-and-narrower V4 might have been better. DeepSeek defers that exploration.
- V5 hint: Section 6 explicitly commits to “more comprehensive and principled investigations to distill the architecture down to its most essential designs.” Expect V5 to revisit the backbone shape from first principles.
6. Hash routing as a load-balance backstop
- Choice: alongside the learned auxiliary-loss-free
noaux_tcrouter, V4 ships 3 hash-routing layers (num_hash_layers: 3) that route tokens to experts deterministically based on token-id hashes. - Why: at 384-routed-experts scale, learned routers can drift toward unbalanced expert utilisation, especially in the early training. Hash routing guarantees uniform-by-construction routing in those layers — a fixed safety net.
- Cost paid: hash routing is content-blind. It probably leaves some specialisation on the table.
- V5 hint: if
noaux_tcmatures further (V3 → V3.2 → V4 has already iterated on it), V5 may drop hash routing entirely. Or it may stay as a free training-stability lever.
7. YaRN context extension instead of native 1M training
- Choice: train the model at 64K positional embeddings (
original_max_position_embeddings: 65536), then extend to 1M via YaRN withfactor: 16. - Why: training at 1M context from the start is enormously expensive — both in raw compute and in long-document data curation. YaRN extension lets DeepSeek concentrate the training budget on quality and depth at 64K, then unlock 1M as an inference-time setting. The hybrid CSA/HCA architecture is what makes the extended context actually work.
- Cost paid: the 1M context is a “stretched” 64K context, not a natively-trained one. The MRCR 1M results (V4-Pro 83.5 vs Opus-4.6 92.9) suggest there’s still recall fidelity left on the table.
- V5 hint: as 1M-context training data becomes more available, expect V5 to push the native training context wider — perhaps 128K or 256K — with a smaller YaRN factor.