DeepSeek V4
Benchmarks
How V4-Pro and V4-Flash compare to V3 and to frontier closed models.
In one paragraph · Last verified 2026-04-27
V4-Pro-Max wins LiveCodeBench (93.5), Codeforces (3206 — ranks 23rd among human candidates), and Apex Shortlist (90.2) outright; ties Putnam-2025 at 120/120 (formal proof). It trails Gemini-3.1-Pro on knowledge-breadth benchmarks (SimpleQA-Verified 57.9 vs 75.6, HLE 37.7 vs 44.4) and Opus-4.6 on long-context recall (MRCR 1M 83.5 vs 92.9). V4-Flash with maximum reasoning effort is often within 1 pp of V4-Pro-High on math/code, making Flash-Max a credible budget alternative to Pro for many workloads. Reasoning-effort scaling is enormous on math (Apex Shortlist Pro Non-Think → Max: 9.2 → 90.2) but modest on knowledge (MMLU-Pro: 82.9 → 87.5).
On this page
- Headline numbers
- V4 vs V3 efficiency (1M-token context)
- Official base-model comparison (Tech report Table 1)
- V4-Pro-Max vs frontier closed/open models (Tech report Table 6)
- V4-Pro vs V4-Flash, across reasoning-effort modes (Tech report Table 7)
- Long-context recall on MRCR (Figure 9)
- Reasoning-effort scaling on HLE and Terminal-Bench (Figure 10)
- Win-rate analysis vs Opus-4.6-Max (Figures 11–12)
- Formal mathematical reasoning (Figure 8)
- Evaluation methodology notes
- Cross-model comparison
Headline numbers
| Benchmark | V4-Pro | Reference | Source |
|---|---|---|---|
| Terminal-Bench 2.0 | 67.9% | Claude Opus 4.7: 65.4% | BuildFastWithAI |
| LiveCodeBench | 93.5% | Claude Opus 4.7: 88.8% | BuildFastWithAI |
| Codeforces (rating) | 3206 | — | BuildFastWithAI |
| Putnam-2025 (formal proof) | 120/120 (V4-Pro Max) | Hybrid informal-formal pipeline | BuildFastWithAI |
| GDPval-AA (agentic) | 1554 | Kimi K2.6: 1484, GLM-5.1: 1535 | Artificial Analysis |
| Artificial Analysis Intelligence Index | 52 (#2 open-weights, behind Kimi K2.6) | — | Artificial Analysis |
All numbers above are third-party reports of DeepSeek’s published numbers, with primary-source verification against the official
DeepSeek_V4.pdfTables 1, 6, and 7 below. Official benchmark figures and the V4-Pro-Max vs frontier head-to-head matrix are embedded in the sections that follow.
 Official DeepSeek V4 benchmark chart 1. Source: api-docs.deepseek.com.
Official DeepSeek V4 benchmark chart 1. Source: api-docs.deepseek.com.
 Official DeepSeek V4 benchmark chart 2. Source: api-docs.deepseek.com.
Official DeepSeek V4 benchmark chart 2. Source: api-docs.deepseek.com.
V4 vs V3 efficiency (1M-token context)
From the official DeepSeek_V4.pdf tech report:
| Metric | V3.2 | V4-Pro | V4-Flash |
|---|---|---|---|
| Single-token inference FLOPs | 100% | ~27% (3.7× lower) | ~10% (9.8× lower) |
| Accumulated KV cache | 100% | ~10% (9.5× smaller) | ~7% (13.7× smaller) |
Source: tech report Section 2.3.4 (“Efficiency Discussion”) and Figure 1; DeepSeek API Docs — V4 Preview Release.
Official base-model comparison (Tech report Table 1)
The tech report’s Table 1 compares base (pre-trained, pre-post-training) models under DeepSeek’s own internal evaluation framework, with consistent few-shot settings. The highest score in each row is bold; the second is italic.
| Benchmark (Metric) | Shots | DeepSeek-V3.2-Base | DeepSeek-V4-Flash-Base | DeepSeek-V4-Pro-Base |
|---|---|---|---|---|
| # Activated params | — | 37B | 13B | 49B |
| # Total params | — | 671B | 284B | 1.6T |
| World knowledge | ||||
| AGIEval (EM) | 0-shot | 80.1 | 82.6 | 83.1 |
| MMLU (EM) | 5-shot | 87.8 | 88.7 | 90.1 |
| MMLU-Redux (EM) | 5-shot | 87.5 | 89.4 | 90.8 |
| MMLU-Pro (EM) | 5-shot | 65.5 | 68.3 | 73.5 |
| MMMLU (EM) | 5-shot | 87.9 | 88.8 | 90.3 |
| C-Eval (EM) | 5-shot | 90.4 | 92.1 | 93.1 |
| CMMLU (EM) | 5-shot | 88.9 | 90.4 | 90.8 |
| MultiLoKo (EM) | 5-shot | 38.7 | 42.2 | 51.1 |
| Simple-QA verified (EM) | 25-shot | 28.3 | 30.1 | 55.2 |
| SuperGPQA (EM) | 5-shot | 45.0 | 46.5 | 53.9 |
| FACTS Parametric (EM) | 25-shot | 27.1 | 33.9 | 62.6 |
| TriviaQA (EM) | 5-shot | 83.3 | 82.8 | 85.6 |
| Language & reasoning | ||||
| BBH (EM) | 3-shot | 87.6 | 86.9 | 87.5 |
| DROP (F1) | 1-shot | 88.2 | 88.6 | 88.7 |
| HellaSwag (EM) | 0-shot | 86.4 | 85.7 | 88.0 |
| WinoGrande (EM) | 0-shot | 78.9 | 79.5 | 81.5 |
| CLUEWSC (EM) | 5-shot | 83.5 | 82.2 | 85.2 |
| Code & math | ||||
| BigCodeBench (Pass@1) | 3-shot | 63.9 | 56.8 | 59.2 |
| HumanEval (Pass@1) | 0-shot | 62.8 | 69.5 | 76.8 |
| GSM8K (EM) | 8-shot | 91.1 | 90.8 | 92.6 |
| MATH (EM) | 4-shot | 60.5 | 57.4 | 64.5 |
| MGSM (EM) | 8-shot | 81.3 | 85.7 | 84.4 |
| CMath (EM) | 3-shot | 92.6 | 93.6 | 90.9 |
| Long context | ||||
| LongBench-V2 (EM) | 1-shot | 40.2 | 44.7 | 51.5 |
Tech report’s takeaway:
“DeepSeek-V4-Flash-Base outperforms DeepSeek-V3.2-Base across a wide array of benchmarks. This advantage is especially evident in world knowledge tasks and challenging long-context scenarios.”
“DeepSeek-V4-Pro-Base demonstrates a further, decisive leap in capability, establishing near-universal dominance over both DeepSeek-V3.2-Base and DeepSeek-V4-Flash-Base.”
Note one weakness: V3.2-Base still wins BigCodeBench (63.9 vs 56.8 / 59.2). DeepSeek does not directly explain this in the tech report excerpt; possibly a training-data composition artifact.
Source: DeepSeek_V4.pdf, Table 1 (page 28).
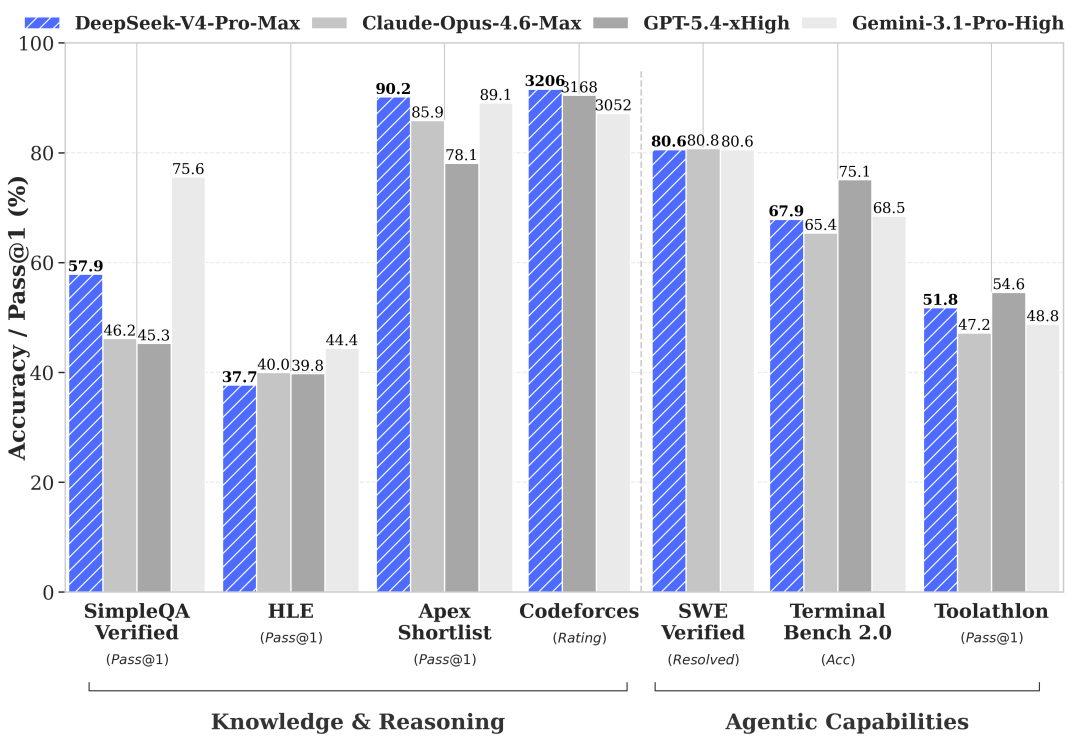
V4-Pro-Max vs frontier closed/open models (Tech report Table 6)
The post-trained-model headline comparison. Max, xHigh, and High denote reasoning effort. Best results in bold; second-best in italic.
| Benchmark (Metric) | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | K2.6 Thinking | GLM-5.1 Thinking | DS-V4-Pro Max |
|---|---|---|---|---|---|---|
| Knowledge & reasoning | ||||||
| MMLU-Pro (EM) | 89.1 | 87.5 | 91.0 | 87.1 | 86.0 | 87.5 |
| SimpleQA-Verified (Pass@1) | 46.2 | 45.3 | 75.6 | 36.9 | 38.1 | 57.9 |
| Chinese-SimpleQA (Pass@1) | 76.4 | 76.8 | 85.9 | 75.9 | 75.0 | 84.4 |
| GPQA Diamond (Pass@1) | 91.3 | 93.0 | 94.3 | 90.5 | 86.2 | 90.1 |
| HLE (Pass@1) | 40.0 | 39.8 | 44.4 | 36.4 | 34.7 | 37.7 |
| LiveCodeBench (Pass@1) | 88.8 | — | 91.7 | 89.6 | — | 93.5 |
| Codeforces (Rating) | — | 3168 | 3052 | — | — | 3206 |
| HMMT 2026 Feb (Pass@1) | 96.2 | 97.7 | 94.7 | 92.7 | 89.4 | 95.2 |
| IMOAnswerBench (Pass@1) | 75.3 | 91.4 | 81.0 | 86.0 | 83.8 | 89.8 |
| Apex (Pass@1) | 34.5 | 54.1 | 60.9 | 24.0 | 11.5 | 38.3 |
| Apex Shortlist (Pass@1) | 85.9 | 78.1 | 89.1 | 75.5 | 72.4 | 90.2 |
| Long context (1M) | ||||||
| MRCR 1M (MMR) | 92.9 | — | 76.3 | — | — | 83.5 |
| CorpusQA 1M (Acc) | 71.7 | — | 53.8 | — | — | 62.0 |
| Agentic | ||||||
| Terminal Bench 2.0 (Acc) | 65.4 | 75.1 | 68.5 | 66.7 | 63.5 | 67.9 |
| SWE Verified (Resolved) | 80.8 | — | 80.6 | 80.2 | — | 80.6 |
| SWE Pro (Resolved) | 57.3 | 57.7 | 54.2 | 58.6 | 58.4 | 55.4 |
| SWE Multilingual (Resolved) | 77.5 | — | — | 76.7 | 73.3 | 76.2 |
| BrowseComp (Pass@1) | 83.7 | 82.7 | 85.9 | 83.2 | 79.3 | 83.4 |
| HLE w/ tools (Pass@1) | 53.1 | 52.0 | 51.6 | 54.0 | 50.4 | 48.2 |
| GDPval-AA (Elo) | 1619 | 1674 | 1314 | 1482 | 1535 | 1554 |
| MCPAtlas Public (Pass@1) | 73.8 | 67.2 | 69.2 | 66.6 | 71.8 | 73.6 |
| Toolathlon (Pass@1) | 47.2 | 54.6 | 48.8 | 50.0 | 40.7 | 51.8 |
“DeepSeek-V4-Pro-Max … significantly outperforms all existing open-source baselines [on SimpleQA-Verified] by a margin of 20 absolute percentage points. Despite these advances, it currently trails the leading proprietary model, Gemini-3.1-Pro.” — tech report Section 5.3.2
“On the Codeforces leaderboard, DeepSeek-V4-Pro-Max currently ranks 23rd among human candidates.”
The standout V4-Pro-Max wins: LiveCodeBench (93.5), Codeforces (3206), Apex Shortlist (90.2). Closest losses: HMMT (95.2 vs GPT-5.4’s 97.7), MMLU-Pro (87.5 vs Gemini’s 91.0). The biggest open weakness vs Gemini: SimpleQA-Verified (57.9 vs 75.6) and HLE (37.7 vs 44.4) — knowledge breadth at the upper bound is still proprietary territory.
Source: DeepSeek_V4.pdf, Table 6 (Section 5.3.2, page 38).
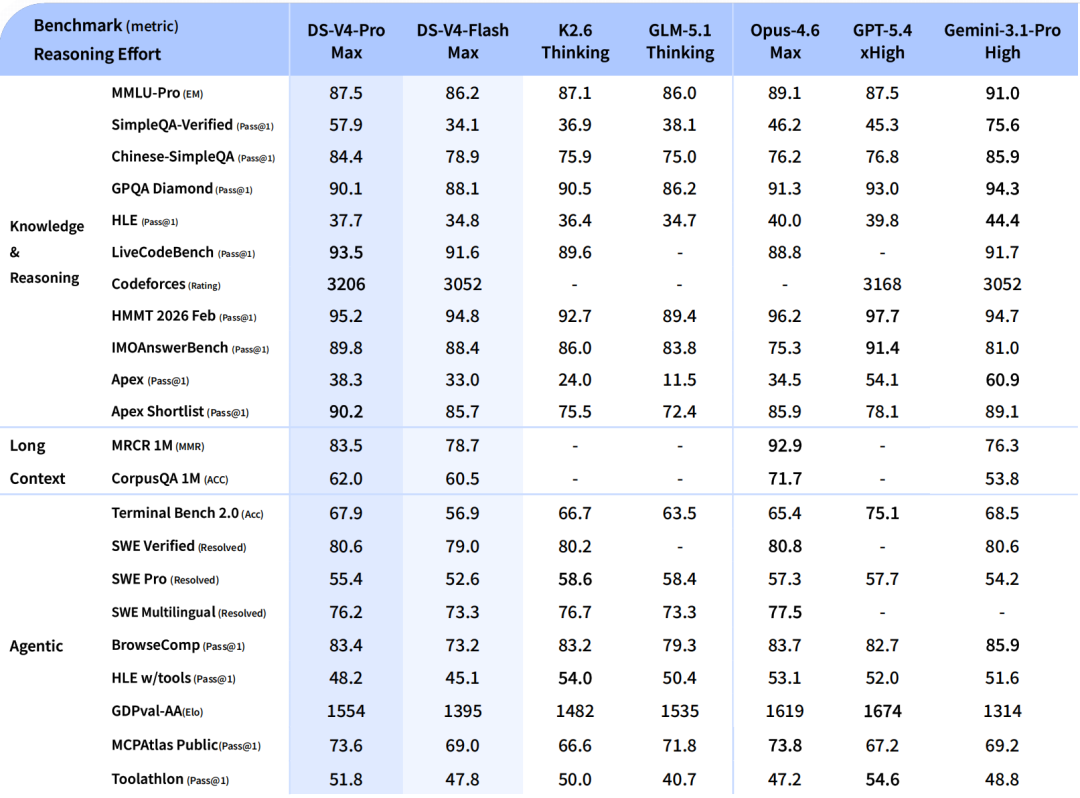
V4-Pro vs V4-Flash, across reasoning-effort modes (Tech report Table 7)
How much does reasoning-effort scaling buy you? V4 supports three modes — Non-Think (no reasoning trace), High, and Max — and Table 7 shows the lift on the same benchmarks.
| Benchmark (Metric) | Flash Non-Think | Flash High | Flash Max | Pro Non-Think | Pro High | Pro Max |
|---|---|---|---|---|---|---|
| Knowledge & reasoning | ||||||
| MMLU-Pro (EM) | 83.0 | 86.4 | 86.2 | 82.9 | 87.1 | 87.5 |
| SimpleQA-Verified (Pass@1) | 23.1 | 28.9 | 34.1 | 45.0 | 46.2 | 57.9 |
| Chinese-SimpleQA (Pass@1) | 71.5 | 73.2 | 78.9 | 75.8 | 77.7 | 84.4 |
| GPQA Diamond (Pass@1) | 71.2 | 87.4 | 88.1 | 72.9 | 89.1 | 90.1 |
| HLE (Pass@1) | 8.1 | 29.4 | 34.8 | 7.7 | 34.5 | 37.7 |
| LiveCodeBench (Pass@1-COT) | 55.2 | 88.4 | 91.6 | 56.8 | 89.8 | 93.5 |
| Codeforces (Rating) | — | 2816 | 3052 | — | 2919 | 3206 |
| HMMT 2026 Feb (Pass@1) | 40.8 | 91.9 | 94.8 | 31.7 | 94.0 | 95.2 |
| IMOAnswerBench (Pass@1) | 41.9 | 85.1 | 88.4 | 35.3 | 88.0 | 89.8 |
| Apex (Pass@1) | 1.0 | 19.1 | 33.0 | 0.4 | 27.4 | 38.3 |
| Apex Shortlist (Pass@1) | 9.3 | 72.1 | 85.7 | 9.2 | 85.5 | 90.2 |
| Long context (1M) | ||||||
| MRCR 1M (MMR) | 37.5 | 76.9 | 78.7 | 44.7 | 83.3 | 83.5 |
| CorpusQA 1M (Acc) | 15.5 | 59.3 | 60.5 | 35.6 | 56.5 | 62.0 |
| Agentic | ||||||
| Terminal Bench 2.0 (Acc) | 49.1 | 56.6 | 56.9 | 59.1 | 63.3 | 67.9 |
| SWE Verified (Resolved) | 73.7 | 78.6 | 79.0 | 73.6 | 79.4 | 80.6 |
| SWE Pro (Resolved) | 49.1 | 52.3 | 52.6 | 52.1 | 54.4 | 55.4 |
| SWE Multilingual (Resolved) | 69.7 | 70.2 | 73.3 | 69.8 | 74.1 | 76.2 |
| BrowseComp (Pass@1) | — | 53.5 | 73.2 | — | 80.4 | 83.4 |
| HLE w/ tools (Pass@1) | — | 40.3 | 45.1 | — | 44.7 | 48.2 |
| MCPAtlas Public (Pass@1) | 64.0 | 67.4 | 69.0 | 69.4 | 74.2 | 73.6 |
| GDPval-AA (Elo) | — | — | 1395 | — | — | 1554 |
| Toolathlon (Pass@1) | 40.7 | 43.5 | 47.8 | 46.3 | 49.0 | 51.8 |
Reading patterns:
- Reasoning-effort lift is enormous on math/code, modest on knowledge. On Apex Shortlist, V4-Pro Non-Think → Max is 9.2 → 90.2 — a 9.8× jump. On MMLU-Pro it’s 82.9 → 87.5.
- Flash-Max can match Pro-High on several benchmarks (e.g. MMLU-Pro 86.2 vs 87.1, SWE Verified 79.0 vs 79.4) — meaning Flash with maximum reasoning effort is often within a point of Pro at moderate effort. The pricing delta (Flash output is ~12× cheaper) makes Flash-Max compelling for cost-sensitive workloads.
- Long-context is where Pro pulls away: MRCR 1M Pro 83.5 vs Flash 78.7; CorpusQA 1M Pro 62.0 vs Flash 60.5.
- Reasoning context windows noted in the eval setup: 8K (Non-Think), 128K (High), 384K (Max). Max mode genuinely uses long context for chain-of-thought, not just the user prompt.
Source: DeepSeek_V4.pdf, Table 7 (Section 5.3.2, page 39).
Long-context recall on MRCR (Figure 9)
How V4-Pro and V4-Flash hold up on the MRCR 1M needle-style retrieval benchmark across context depth:
 DeepSeek-V4 series performance on the MRCR task — accuracy plotted as context length grows. Source: tech report Figure 9 (page 41).
DeepSeek-V4 series performance on the MRCR task — accuracy plotted as context length grows. Source: tech report Figure 9 (page 41).
The chart shows recall fidelity holding up well past 500K tokens for V4-Pro, with V4-Flash trailing as expected. Context-recall is the axis where Opus-4.6 retains a lead at the same depth (see Table 6 above), but V4 makes the long context cheap.
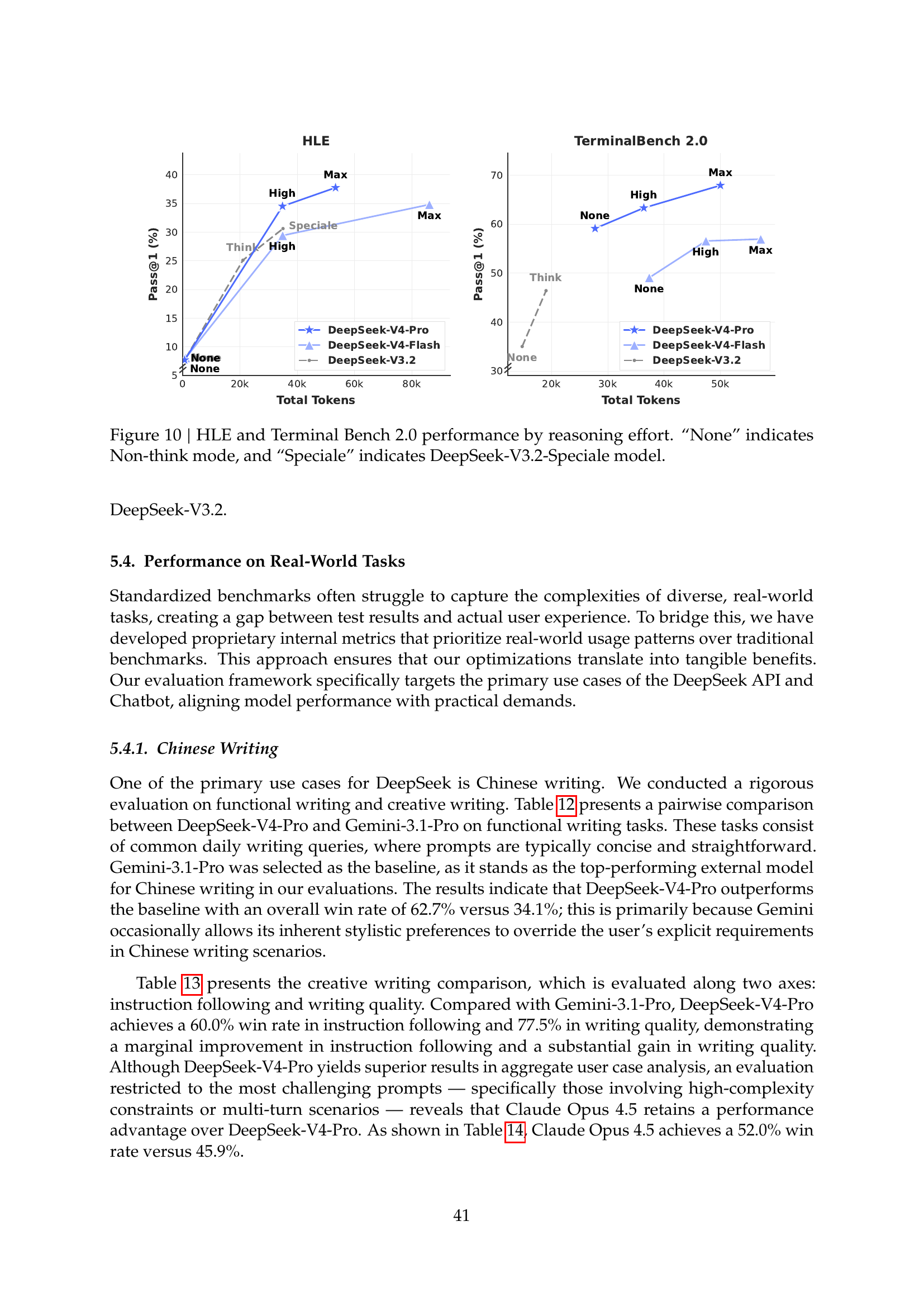
Reasoning-effort scaling on HLE and Terminal-Bench (Figure 10)
How much does dialing up reasoning effort actually buy? Figure 10 plots HLE (Pass@1) and Terminal-Bench 2.0 (Acc) as a function of reasoning-effort mode (None / High / Max), comparing V4-Pro, V4-Flash, and the proprietary frontier:
 “None” indicates Non-Think mode. Source: tech report Figure 10 (page 42).
“None” indicates Non-Think mode. Source: tech report Figure 10 (page 42).
The lift on HLE from None → Max is non-linear: ~30 percentage points for both Pro and Flash, with a sharp inflection between None and High. Terminal-Bench shows a flatter curve — most of the gain happens already at High effort, with Max delivering only marginal additional uplift.
Win-rate analysis vs Opus-4.6-Max (Figures 11–12)
DeepSeek conducted a head-to-head qualitative analysis of V4-Pro-Max vs Opus-4.6-Max across analysis, generation, and other dimensions:
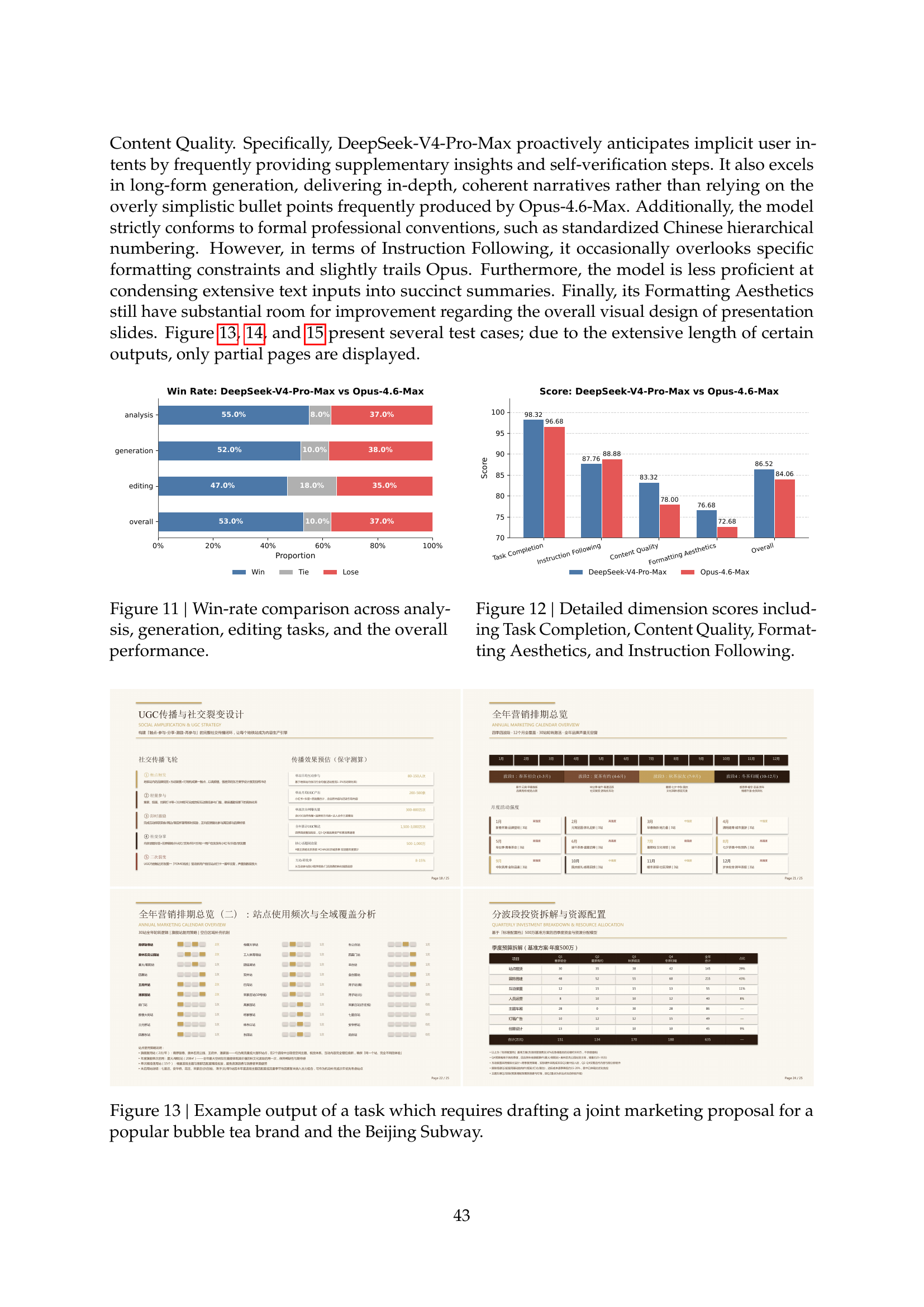 Win-rate by dimension and per-dimension scores. Source: tech report Figures 11–12 (page 43).
Win-rate by dimension and per-dimension scores. Source: tech report Figures 11–12 (page 43).
Headline numbers from the chart:
- Analysis: V4-Pro-Max wins 55%, ties 8%, loses 37% to Opus-4.6-Max.
- Generation: V4-Pro-Max wins 52%, ties 10%, loses 38%.
DeepSeek’s own qualitative summary:
“DeepSeek-V4-Pro-Max proactively anticipates implicit user intents by frequently providing supplementary insights and self-verification steps. It also excels in long-form generation, delivering in-depth, coherent narratives rather than relying on the overly simplistic bullet points frequently produced by Opus-4.6-Max … However, in terms of Instruction Following, it occasionally overlooks specific formatting constraints and slightly trails Opus. Furthermore, the model is less proficient at condensing extensive text inputs into succinct summaries. Finally, its Formatting Aesthetics still have substantial room for improvement regarding the overall visual design of presentation slides.”
So V4-Pro-Max’s edge is on depth and proactive insight; its weak spots vs Opus are strict instruction following, summarisation, and visual-design aesthetics in slide-style output.
Source: tech report Figures 11–12 and surrounding analysis (page 43).
Formal mathematical reasoning (Figure 8)
V4 demonstrates strong performance on formal Lean v4 theorem-proving. Two regimes:
Practical regime — Putnam-200 Pass@8 (minimal tools, bounded sampling, open-source LeanExplore):
| Model | Score |
|---|---|
| Seed-1.5-Prover | 26.50 |
| Gemini-3-Pro | 26.50 |
| Seed-2.0-Pro | 35.50 |
| DeepSeek-V4-Flash-Max | 81.00 |
Frontier regime — Putnam-2025 (hybrid formal-informal reasoning, substantial compute):
| Model | Score |
|---|---|
| Aristotle | 100/120 |
| Seed-1.5-Prover | 110/120 |
| Axiom | 120/120 |
| DeepSeek-V4 | 120/120 |
“DeepSeek-V4 demonstrates strong performance on formal mathematical task under both agentic and compute-intensive settings. Under an agentic setup, it achieves state-of-the-art results … outperforming prior models such as Seed Prover. With a more compute-intensive pipeline, performance further improves, surpassing systems including Aristotle and matching the best known results under this setting.” — tech report Section 5.3.2

Source: DeepSeek_V4.pdf, Figure 8 (page 40).
Evaluation methodology notes
For full reproducibility, the tech report (Section 5.3.1) specifies:
- Codeforces: 14 Codeforces Division-1 contests (May–Nov 2025), 114 problems total. 32 candidates per problem; 10 sampled into a submission sequence; OpenAI-style penalty scoring. Final rating is the average of expected ratings across contests.
- Reasoning context windows: 8K (Non-Think), 128K (High), 384K (Max).
- Math template:
"{question}\nPlease reason step by step, and put your final answer within \boxed{}."— for V4-Pro-Max, an extended template that accepts proof-shaped answers. - Code-agent harness: bash + file-edit tool, 500 max steps, 512K context.
- Search-agent harness: websearch + Python, 500 steps, 512K context, V3.2’s “discard-all” context-management strategy.
- Formal math: Lean v4.28.0-rc1, up to 500 tool calls, max reasoning effort. Both an agentic setting and a hybrid informal-then-formal pipeline.
- Caveats: K2.6 and GLM-5.1 entries are blank where their APIs were too rate-limited to respond. GPT-5.4’s API failed on the 1M-context evaluations.
Cross-model comparison
The full V4-Pro-Max vs Opus-4.6-Max vs GPT-5.4-xHigh vs Gemini-3.1-Pro-High vs K2.6 vs GLM-5.1 head-to-head — covering MMLU-Pro, SimpleQA-Verified, GPQA Diamond, HLE, LiveCodeBench, Codeforces, HMMT 2026 Feb, IMOAnswerBench, Apex, MRCR 1M, CorpusQA 1M, Terminal Bench 2.0, SWE Verified, SWE Pro, SWE Multilingual, BrowseComp, HLE w/ tools, GDPval-AA, MCPAtlas, and Toolathlon — is in the V4-Pro-Max vs frontier closed/open models section above (Table 6 from the tech report).